
Google officially released a document explaining the outcomes of its use of evolutionary AutoML to automatically search for neural network architectures. Can we leverage existing computing resources to programmatically improve image classifiers at scale? Can we achieve effective solutions with minimal expert involvement? How advanced is artificial neural network technology today?
The brain has evolved over millions of years, from the simple nervous system of a worm 500 million years ago to the complex structures seen in humans today. For instance, the human brain can effortlessly perform a wide range of tasks, such as quickly identifying whether a visual scene contains animals or buildings.
To replicate this ability, neural networks typically require extensive expert design after years of research to solve specific tasks—like object detection in images, genetic variation discovery, or medical diagnosis. Ideally, people want an automated way to generate the optimal network structure for any given task.
One approach to achieving this is through evolutionary algorithms. Traditional research in this area has laid the groundwork, allowing large-scale application of these techniques today. Many research teams, including OpenAI, Uber Labs, Sentient Labs, and DeepMind, are actively exploring this domain. Google’s Brain team has also been investigating Automated Learning (AutoML).
In addition to learning-based methods like reinforcement learning, can we use available computing power to enhance image classifiers on a large scale? Can we get a solution with very little expert input? How advanced are neural networks today? We address these questions in two papers.
In the paper "Large-Scale Evolution of Image Classifiers" published at ICML in 2017, we created an evolutionary process using simple modules and initial conditions. The basic idea was to start from scratch and evolve high-quality models through large-scale computation. Starting with a very simple network, we eventually obtained a model comparable to manually designed ones. This process required minimal human intervention, which is promising.
For example, some users may need better models but lack the time to become machine learning experts. Naturally, the next question arises: could combining manually designed networks with evolutionary ones yield better results than either method alone? In a 2018 paper titled "Regularized Evolution for Image Classifier Architecture Search," we introduced more complex modules and improved initial conditions to build evolutionary processes.
We also utilized Google's new TPUv2 chip for computing, combining modern hardware, expert knowledge, and evolution to develop state-of-the-art models on popular datasets like CIFAR-10 and ImageNet.
A simple way to introduce the first paper is by describing a mutation and selection process that continuously improves the network.
Next, let's look at a simple example to explain the first paper. In the image below, each point represents a neural network trained on the CIFAR-10 dataset. Initially, thousands of identical simple seed models were used—models without hidden layers. Starting with a simple model is crucial. If we begin with a high-quality model, it might lead to better results faster. However, starting with a basic model allows the process to gradually progress.
At each step, two networks are randomly selected. The one with higher accuracy becomes the parent, and a child is generated by copying and mutating. The less accurate network is discarded, while others remain unchanged. This cycle resembles human evolution.
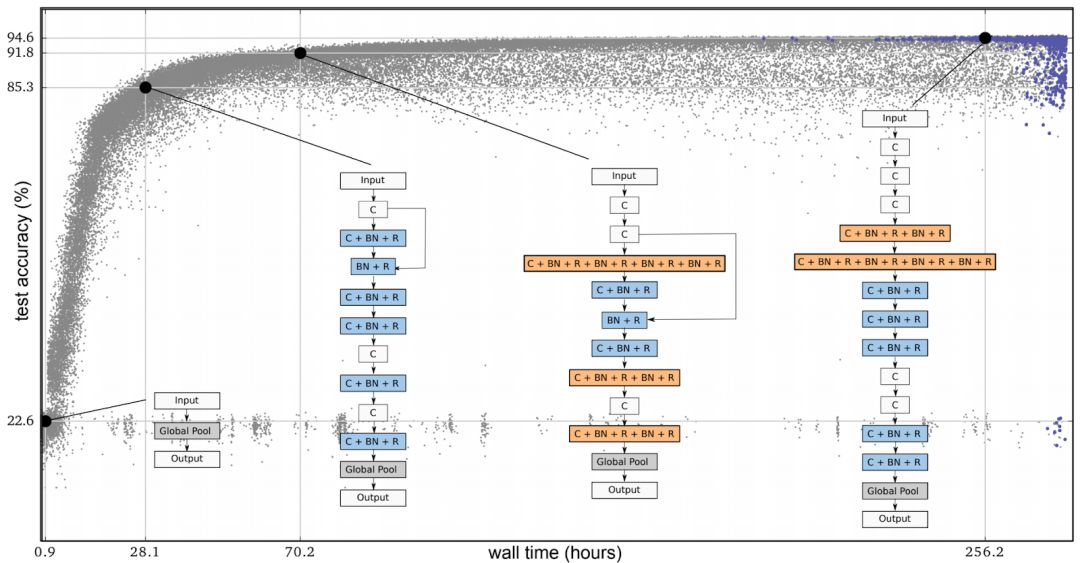
Figure 1: Schematic diagram of evolutionary experiments. Each point represents an individual in the population. These four figures show an example of the structure found, including the best individuals and their ancestors.
The mutations in our paper are purposeful simplifications, such as randomly removing a convolution layer, adding skip connections between layers, or adjusting the learning rate. This approach highlights the potential of evolutionary algorithms in terms of performance, not just the quality of the search space.
For instance, if during evolution, we used a single mutation to convert a seed network into an Inception-ResNet classifier, it might seem like an ideal result. However, this would be misleading, as it implies hardcoding the final answer. With simple mutations, the algorithm must discover the solution itself, which is the true essence of evolution.
In the experiment, the simple mutation and selection process led to continuous improvements in the network over time, achieving high test accuracy even when the test set had never been seen before. Additionally, the network inherited the weights of its parent, meaning the system was not only evolving the architecture but also optimizing hyperparameters during the search. No expert input was needed once the experiment started.
Although we minimized researcher involvement through a simple initial architecture and intuitive mutations, a lot of expert knowledge was embedded in the modules. These include key innovations like convolutions, ReLUs, and batch normalization. We were evolving an architecture built from these components. The term “architecture†is not accidental—it’s like building a house with high-quality bricks.
Evolution can indeed match or surpass manual design to create the most advanced models.
After publishing the first paper, we aimed to narrow the search space by reducing algorithm choices to make the process easier to manage. Using our architectural framework, we removed all possible error-prone methods from the search space, similar to ensuring walls are placed correctly in a house.
Like neural network architecture search, the algorithm can be implemented by fixing the general structure of the network. Zoph et al. introduced an inception-like module in a 2017 paper that proved highly effective. Their idea was to use repeating units called cells, with a fixed stack but variable cell architecture.
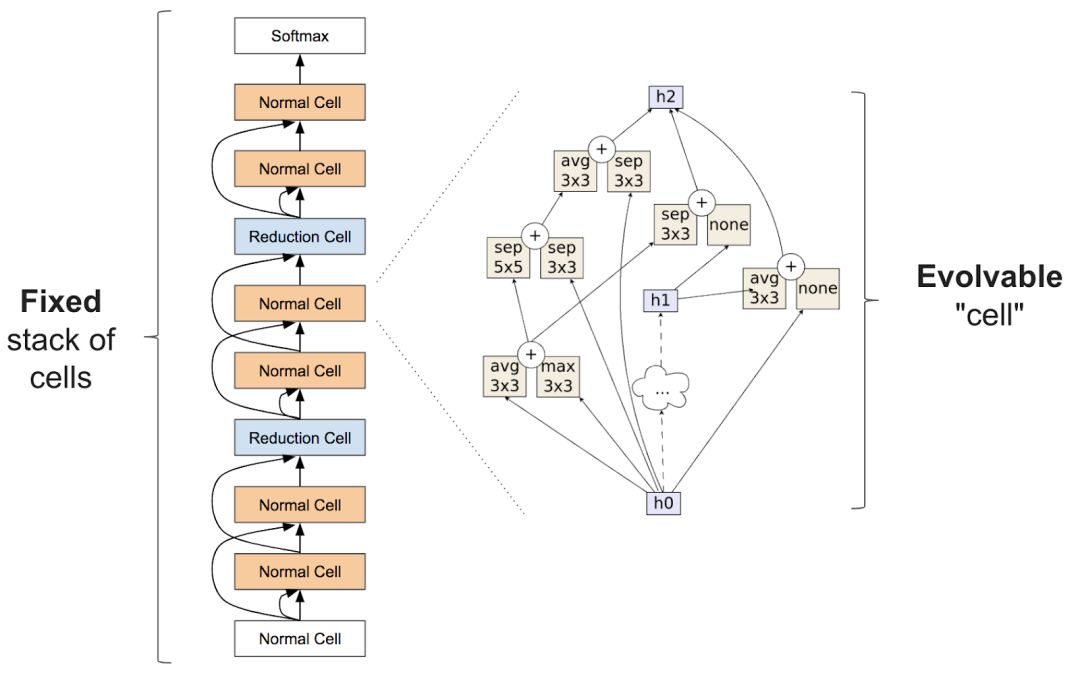
Figure 2: Structural blocks proposed in Zoph et al. (2017). The left chart shows the full network, processing data through repeating units. The right chart illustrates the internal structure of a cell. Our goal was to build a cell that produces an accurate network.
In our second paper, "Regularized Evolution for Image Classifier Architecture Search," we demonstrated how evolutionary algorithms can be applied to this search space. Mutations involved randomly reconnecting inputs or replacing operations within the cells. These variations were still simple, but the initial conditions were more sophisticated, allowing models to conform to expert-designed cellular structures.
While the elements in the seed models were random, we no longer started with a simple model, making high-quality models more accessible. If the evolutionary algorithm was effective, the final network should significantly outperform existing ones. Our papers show that evolution can indeed match or exceed manual design to produce the most advanced models.
Control variable comparison
Although the mutation-selection process is straightforward, other approaches like random search or reinforcement learning might achieve similar results. To evaluate this, our second paper compared different methods under the same conditions.
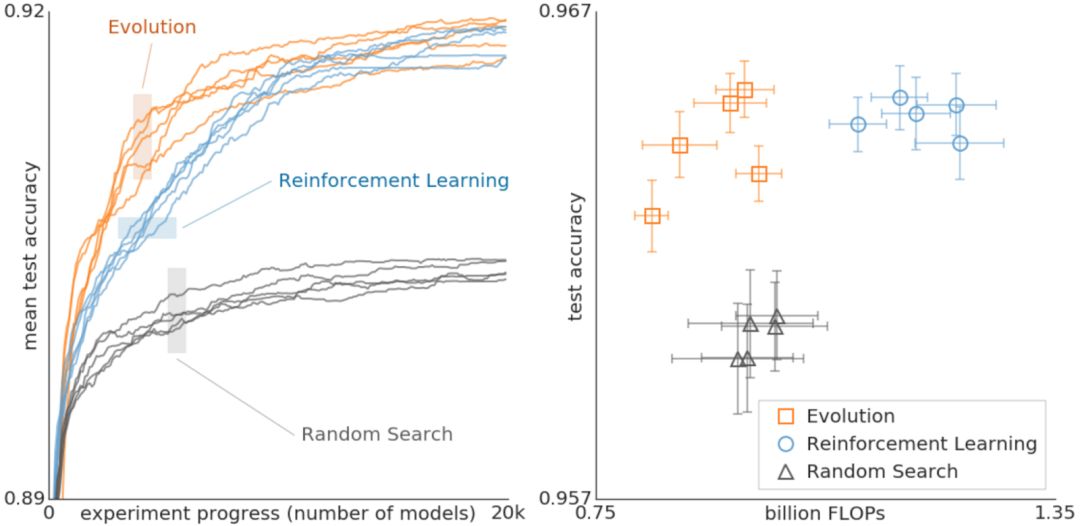
Figure 3: Comparison of evolution, reinforcement learning, and random search for architectural search. These experiments were conducted on the CIFAR-10 dataset, using the same search space as Zoph et al.
The data shows that evolution outperformed reinforcement learning in the early stages of the search, which is important when computing resources are limited. Evolution was also more robust to changes in datasets or search spaces.
Overall, the purpose of this comparison was to provide researchers with insights into the computational cost of various methods. We hoped to offer practical case studies showing how different search algorithms interact. For example, the results showed that evolution could achieve high precision with fewer floating-point operations.
An important feature of the evolutionary algorithm in our second paper is regularization. Instead of eliminating the worst-performing networks, we removed the oldest ones regardless of their performance. This increased the robustness of the optimization task and ensured more accurate models. Since we didn’t allow weight inheritance, all networks had to be trained from scratch, ensuring that only the best-performing ones survived.
In other words, because a model might appear accurate by chance, training noise means that the same architecture could have varying accuracy. Only those that maintained accuracy across generations could survive, giving them a better chance of being re-selected. More details about this idea can be found in the paper.
The most advanced model we’ve evolved is called "AmoebaNets," one of the latest achievements in our AutoML efforts. These experiments required extensive computation using hundreds of GPUs/TPUs. Just as modern computers now outperform old machines from decades ago, we hope these experiments will eventually become accessible to many households. Here, we simply aim to give everyone a glimpse of what the future holds.
A Linux PC for IoT is a computing device that runs on the Linux operating system and is designed to be integrated into IoT applications.
Linux is known for its stability, security, and open-source nature. It can be customized and optimized for specific IoT tasks, making it an ideal choice for developers. For example, it can be configured to run with minimal resources, which is important for power-constrained IoT devices.
An IoT Industrial Computer is a ruggedized computing device designed for industrial environments and IoT applications.
An IoT Industrial PC is similar to an IoT industrial computer but often has a more traditional PC form factor.
In conclusion, Linux PCs for IoT, IoT industrial computers, IoT industrial PCs, and Linux industrial PCs are essential components of the IoT and industrial automation ecosystems. They offer a combination of computing power, connectivity, ruggedness, and customizability to meet the diverse needs of modern industrial applications. Whether it's for monitoring and controlling industrial processes, collecting and analyzing sensor data, or enabling smart manufacturing, these devices play a crucial role in driving the digital transformation of industries.
Linux Pc For Iot,Iot Industrial Computer,Iot Industrial Pc,Linux Industrial Pc
Shenzhen Innovative Cloud Computer Co., Ltd. , https://www.xcypc.com