
Deep learning requires a lot of calculations. It usually contains a neural network with many nodes, and each node has many connections that need to be constantly updated during the learning process. In other words, each layer of the neural network has hundreds of identical artificial neurons performing the same calculations. Therefore, the structure of the neural network is applicable to the type of computation that the GPU (Graphics Processing Unit) can perform efficiently (the GPU is specifically designed to compute the same instructions in parallel).
With the rapid development of deep learning and artificial intelligence over the past few years, we have also seen the introduction of many deep learning frameworks. The deep learning framework was created to efficiently run deep learning systems on the GPU. These deep learning frameworks all rely on the concept of computational graphs, which define the order of calculations that need to be performed. In these frameworks you are using a language that can build computational graphs, and the language's execution mechanism is different from the mechanism of its host language itself. The calculation map can then be optimized and run in parallel on the target GPU.
In this article, I want to introduce you to the five main frameworks that drive the development of deep learning. These frameworks make it easier for data scientists and engineers to build deep learning solutions for complex problems and perform more complex tasks. This is just a small part of many open source frameworks, supported by different technology giants and pushing each other for faster innovation.

1. TensorFlow (Google)
TensorFlow was originally developed by researchers and engineers at the Google Brain Team. Its purpose is to face deep neural networks and machine intelligence research. Since the end of 2015, TensorFlow's library has been officially open sourced on GitHub. TensorFlow is very useful for quickly performing graphics-based calculations. The flexible TensorFlow API can deploy models between multiple devices through its GPU-enabled architecture.
In short, the TensorFlow ecosystem has three main components:
The TensorFlow API written in C++ contains APIs for defining models and using data training models. It also has a user friendly Python interface.
TensorBoard is a visual toolkit for analyzing, visualizing and debugging TensorFlow calculations.
TensorFlow Serving is a flexible, high-performance service system for deploying pre-trained machine learning models in production environments. Serving is also written in C++ and is accessible via the Python interface, allowing you to instantly switch from the old mode to the new mode.
TensorFlow has been widely used in academic research and industrial applications. Some notable current uses include Deep Speech, RankBrain, SmartReply and On-Device Computer Vision. You can view some of the best official uses, research models, examples, and tutorials in TensorFlow's GitHub project.

Let's look at a running example. Here, I train a 2-layer ReLU network based on L2 loss with random data on TensorFlow.

This code has two main components: defining the calculation graph and running the graph multiple times. When defining the calculation graph, I create placeholders for input x, weights w1 and w2, and target y for placeholders. Then in forward propagation, I calculate the prediction of the target y and the loss value (the loss value is the L2 distance between the true value of y and the predicted value). Finally, I asked Tensorflow to calculate the gradient loss for w1 and w2.
After completing the calculation graph build, I create a session box to run the calculation graph. Here I created a numpy array that will populate the placeholders (placeholders) created during the construction and provide their values ​​to x, y, w1, w2. To train the network, I repeatedly run the calculation graph, use the gradient to update the weights and then get the numpy array of loss, grad_w1 and grad_w2.
Keras: Premium Packaging
The deep learning framework runs at two levels of abstraction: low-level mathematics and neural network basic entity implementation (TensorFlow, Theano, PyTorch etc.) and high-level - using low-level basic entities to implement neural network abstractions, such as models And layers (Keras).
Keras is a wrapper for its backend library, which can be TensorFlow or Theano - which means that if you are using Keras with TensorFlow as the backend library, you are actually running TensorFlow code. Keras has considered many basic details for you because it is aimed at users of neural network technology and is very suitable for those who practice data science. It supports simple and fast prototyping, supports multiple neural network architectures, and runs seamlessly on CPU/GPU.
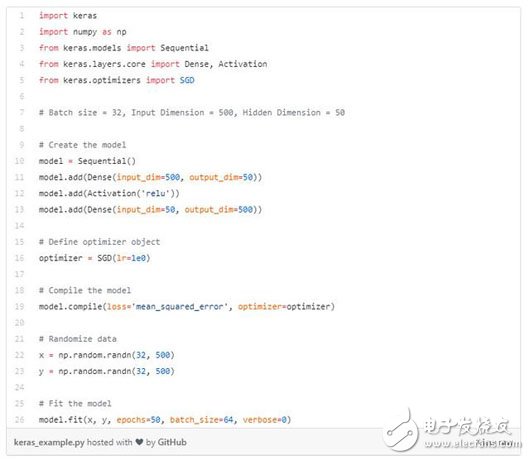
In this example, for a neural network similar to the one in the previous example, I first defined the model object as a series of layers and then defined the optimizer object. Next, I build the model, specify the loss function, and train the model with a single "fit" curve.
2. Theano (University of Montreal)
Theano is another Python library for fast numerical calculations that can be run on a CPU or GPU. It is an open source project developed by the Montreal Learning Algorithms Group at the University of Montreal. Some of its most prominent features include transparent use of the GPU, tight integration with NumPy, efficient symbol differentiation, speed/stability optimization, and extensive unit testing.
Unfortunately, Youshua Bengio (head of MILA Labs) announced in November 2017 that they will no longer actively maintain or develop Theano. The reason is that most of the innovative technologies that Theano has introduced over the years are now adopted and refined by other frameworks. If you are interested, you can still contribute to its open source library.

Theano is similar to TensorFlow in many ways. So let's take a look at another code example that uses the same batch and input/output sizes to train the neural network:
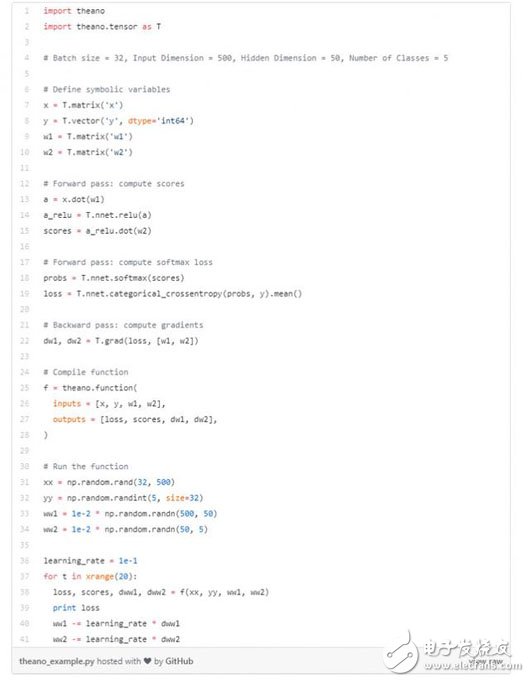
I first defined the Theano symbol variable (similar to the TensorFlow placeholder). For forward propagation, I calculate predictions and losses; for backpropagation, I calculate gradients. Then I compile a function that calculates the loss, score and gradient based on the data and weights. Finally, I ran this function multiple times to train the network.
3. PyTorch (Facebook)
Pytorch is very popular among academic researchers and is a relatively new deep learning framework. The Facebook Artificial Intelligence Research Group developed pyTorch to address some of the problems encountered in its predecessor, Torch. Due to the low popularity of the programming language Lua, Torch can never experience the rapid development of Google TensorFlow. As a result, PyTorch uses the original Python imperative programming style that is already familiar to many researchers, developers, and data scientists. It also supports dynamic computational graphs, a feature that makes it attractive to researchers and engineers working on time series and natural language processing data.
So far, Uber has used PyTorch best, and it has built Pyro, a universal probabilistic programming language that uses PyTorch as its backend. PyTorch's ability to dynamically differentiate execution and build gradients is very valuable for random operations in probabilistic models.

PyTorch has 3 levels of abstraction:
Tensor: imperative ndarray, but running on the GPU
Variable: Calculate nodes in the graph; store data and gradients
Module: neural network layer; can store state or learnable weights
Here I will focus on the tensor abstraction level. PyTorch tensors are like numpy arrays, but they can be run on the GPU. There is no built-in computational graph or the concept of gradient or deep learning. Here, we use PyTorch Tensors to fit a 2-layer network:

As you can see, I first create a random tensor for the data and weights. Then I calculate the predictions and losses in the forward propagation process and manually calculate the gradients during the backpropagation process. I also set the gradient descent step size for each weight. Finally, I trained the network by running this feature multiple times.
4. Torch (NYU / Facebook)
Let's talk about Torch. It is Facebook's open source machine learning library, scientific computing framework and scripting language based on the Lua programming language. It provides a wide range of deep learning algorithms and has been used by Facebook, IBM, Yandex and other companies to solve hardware problems with data streams.

As a direct ancestor of PyTorch, Torch shares a lot of C backends with PyTorchg. Unlike PyTorch, which has three levels of abstraction, Torch has only two: tensors and modules. Let's try a code tutorial that uses Torch tensors to train a two-layer neural network:
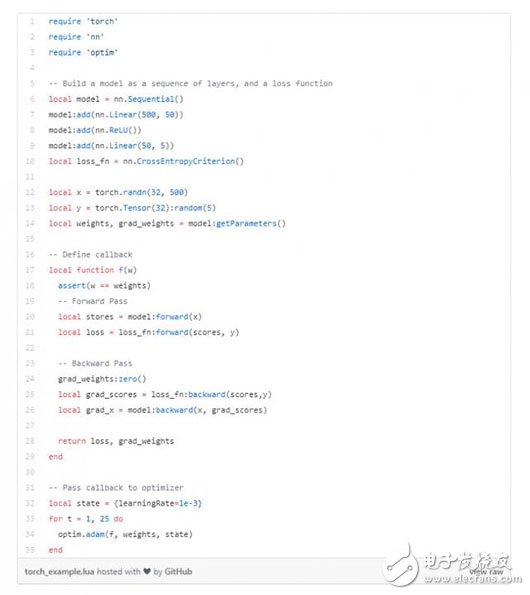
Initially, I built a multi-layer neural network model and a loss function. Next, I define a backtracking function that enters weights and produces a loss/gradient on the weights. Inside the function, I calculate the predictions and losses in forward propagation, as well as the gradients in backpropagation. Finally, I repeatedly pass the backtracking function to the optimizer for optimization.
5. Caffe (UC Berkeley)
Caffe is a deep learning framework that combines expressiveness, speed and modularity. Developed by the Berkeley Artificial Intelligence Research Group and the Berkeley Center for Vision and Learning. Although its kernel is written in C++, Caffe has Python and Matlab related interfaces. This is very useful for training or fine-tuning the feedforward classification model. Although it is not used much in research, it is still very popular with deployment models, as evidenced by community contributors.

In order to use Caffe to train and fine tune the neural network, you need to go through 4 steps:
Convert data: We read the data files, then clean and store them in a format that Caffe can use. We will write a Python script for data preprocessing and storage.
Defining the model: The model defines the structure of the neural network. We choose the CNN architecture and define its parameters in a configuration file with a .prototxt extension.
Define the solver: The solver is responsible for model optimization and defines all the information about how to make a gradient drop. We define the solver parameters in a configuration file with a .prototxt extension.
Training model: Once we have the model and solver ready, we train the model by calling caffe binary from the terminal. After training the model, we will get the trained model in a file with the extension .caffemodel.
I won't show code for Caffe, but you can check out a tutorial on Caffe's homepage. In general, Caffe is very useful for feedforward networks and fine-tuning existing networks. You can easily train your model without writing any code. Its Python interface is very useful because you can deploy the model without using Python code. The downside is that you need to write C++ kernel code for each new GPU layer (under Caffe). Therefore, the construction of large networks (AlexNet, VGG, GoogLeNet, ResNet, etc.) will be very troublesome.
Which deep learning framework should you use?
Since Theano is no longer being developed, Torch is written in a Lua language that is not familiar to many people. Caffe is still in its early maturity stage, and TensorFlow and PyTorch are the preferred frameworks for most deep learning practitioners. Although both frameworks use Python, there are some differences between them:
PyTorch has a cleaner and cleaner interface that is easier to use and is especially suitable for beginners. Most of the code is written more intuitively than fighting the library. In contrast, TensorFlow has a more complex, small, ambiguous library.
However, TensorFlow has more support and a very large, vibrant and helpful community. This means TensorFlow's online courses, code tutorials, documentation and blog posts are more than PyTorch.
In other words, PyTorch is a new platform with many interesting features that have not yet been improved. But what is amazing is that PyTorch has made great achievements in just over a year.
TensorFlow is more scalable and very compatible with distributed execution. It supports all systems from GPU-only to large systems involving heavy-duty distributed reinforcement learning based on real-time trials and errors.
Most importantly, TensorFlow is "definition-run", defining conditions and iterations in the graph structure, and then running it. On the other hand, PyTorch is "defined by operation", where the graph structure is defined in real time during the forward calculation process. In other words, TensorFlow uses static calculation graphs, while PyTorch uses dynamic computation graphs. Dynamic graph-based methods provide easier-to-use debugging capabilities and greater processing power for complex architectures such as dynamic neural networks. Static graph-based methods can be more easily deployed to mobile devices, easier to deploy to a more diverse architecture, and have the ability to compile ahead of time.
As a result, PyTorch is better suited for rapid prototyping for enthusiasts and small projects, while TensorFlow is better suited for large-scale deployments, especially when considering cross-platform and embedded deployments. TensorFlow has stood the test of time and is still widely used. It has more features and better scalability for large projects. PyTorch is easier to learn, but it doesn't have the same integrated integration as TensorFlow. This is useful for small projects that need to be done quickly, but not the best choice for product deployment.

Written at the end
The above list is only a more prominent framework in many frameworks, and most support the Python language. In the past few years, several new deep learning frameworks have been released, such as DeepLearning4j (Java), Apache's MXNet (R, Python, Julia), Microsoft CNTK (C++, Python) and Intel's Neon (Python). Each framework is different because they are developed by different people for different purposes. A general understanding of the whole will help you solve your next deep learning problem. Easy to use (in terms of architecture and processing speed), difficulty in obtaining GPU support, tutorials and training materials, neural network modeling capabilities, and supported languages ​​are all important considerations when choosing the best option for you.
Vaporesso Vape pen, Manufacture Vaporesso Vape, Wholesale Vaporesso Vapes
Shenzhen Xcool Vapor Technology Co.,Ltd , http://www.xcoolvapor.com