
Lei Fengnet (search for "Lei Feng Net" public concern) : Qu Xiaofeng, Ph.D. student of Human Biometrics Research Center, Hong Kong Polytechnic University. Lei Feng network exclusive article, reproduced please contact the authorization.
Recently, the two cloud computing platforms I have used, Sense.io and getdatajoy.com, will soon be gone. The former was acquired and has been closed for individual users; the latter is due to close on January 2, 2017.
Today, with the outbreak of artificial intelligence, two cloud computing platforms that should have been the core of intelligent computing not only failed to rise in the wind, but also turned to the dragon, but fell on the threshold of a new era and had to arouse people's thoughts.
| Sense.io - On-demand computing power
On Sense.io, each project can run on a platform with different computing power. A single project can use multiple virtual CPUs and either large or small memory space.
Sense.io is a cloud computing platform for data scientists that can dynamically allocate computing power. Simply put, it is "Data Scientist GitHub." On Sense, data scientists can collaborate with others and generate data reports.
On March 22, 2016, Sense announced its acquisition by Cloudera, a big data software company. Tristan Zajonc and Anand Patil, founders of Sense, announced the acquisition announcement on the Sense blog, and announced that the free and personal service was closed on April 31, 2016.
On Sense, users can use Python, R, and Julia to write code, perform algorithm experiments, build models, and then select a cloud computing platform (virtual CPU, memory) running with appropriate computing power according to the algorithm's needs and cost. Output, save the result. The running program can be a one-time function, or it can be single-stepped using an interactive execution environment like Jupyter to see the output. The output result can be a data file, such as CSV, which can be a png, jpg, or other format image, or it can be displayed in a javascript dynamic chart. Finally, markdown and pdf reports can also be generated.
I used to perform some data analysis with Sense.io. Its greatest advantage is the configurable nature of computing power. In the early stages of the experiment, using slightly less computing power, using a single CPU to examine the data, debugging the algorithm, testing the hypothesis. When the experimental process is relatively clear and clear, after the code runs, you can switch to large computing power, use 16, 32, 64 cores, and large memory to load all the data for operation and obtain experimental results as soon as possible. In particular, experiments in the same direction can be used to quickly develop multiple experiments in parallel by simply copying items, modifying parameters, adding functions, or adjusting processes. Data can be uploaded to AWS data servers in the same room, such as S3, DynamoDB, or Redshift, to facilitate shared access for different projects or multiple rapid accesses to the same project (sense.io is built on top of the AWS infrastructure).
In fact, doing scientific research or doing business data analysis will encounter such problems. In the early stages of designing algorithms or experiments, it is not always a matter of programming and operations. Checking and cleaning data and thinking about taking up a lot of time in the early stage.
Until there is a clearer direction, when we need to use data and results to verify ideas, we need a lot of even massive computing. Of course, the two situations are often alternated, thinking about debugging over time; running a large amount of data over time to see the overall output. When doing batch operations, even grab someone's computer to run the experiment. Use Sense.io this kind of scheme, can make full use of computing ability effectively. On the one hand, it will not waste a lot of computing power at the beginning of proof of concept; on the other hand, when it is needed, it can quickly expand the clones and mobilize a large amount of computing power in a short period of time to get results quickly.
Sense.io is more flexible and useful than other existing websites. It is pre-configured with a programming environment, including the most commonly used open source language development environments for data analysis such as Python, R, and Julia, and can be used directly. You do not need to configure a virtual machine, configure a virtual network, install a system, and install a software environment.
At the same time, collaboration and sharing have also become quite simple. Login directly to an online account and enter the same project to collaborate. Or directly clone a current working image project to others to take over the development.
From a server operation point of view, this is a more reasonable plan. The peak usage of each user is different, and the use of different user peaks can improve the utilization of the server. Even by adjusting the price of peak-to-peak computing power, it is possible to further suppress the peak of Pinggu.
Unfortunately, after being acquired by Cloudera, Sense has closed down for individual users, and it is not known whether Cloudera will open up Sense's technology to dynamically adjust computing power in the future.
| DataJoy - Integration of Academic documentation and code
Running Kerras-based full-connection deep network learning on DataJoy to identify examples of MNIST handwritten characters.
On August 3, 2016, DataJoy co-founders James Allen and Henry sent a closing notice to all users. Announced that the website will be closed on January 2, 2017, when the account will no longer be able to log in, the balance of the paid user account will be refunded.
DataJoy is a cloud computing project launched two years ago by the ShareLaTeX team. On the DataJoy website, you can use Python and R for data analysis and programming learning. Any computer, just open the browser to log on to getdatajoy.com this site, you can immediately Python and R programming, debugging, analysis of data, output results, easy programming teaching, eliminating the first lesson of all programming courses to install the software configuration environment Chaos scenes can be started directly. And a stable environment that can be accessed anytime and anywhere and can be simply cloned provides practitioners with a stable, easy-to-expand, and shared standard work environment.
The DataJoy team stated in the site notice email sent to users that there are already many successful competing products in the market, so the competition is fierce. In the past two years, although DataJoy has been helpful to a small number of users, it has not become popular on a large scale. Although some teachers use DataJoy to teach Python and R, this is not enough to support the continued development of DataJoy. If the business cannot succeed, and the technical team also maintains ShareLaTeX, they can only choose to close DataJoy.
In simple terms, it means that the business model cannot be sustained, there is no profit and investment, and it has to be closed. This can also be verified from some aspects. In the Chinese science and technology media, there is no relevant news at all. Only a traveler's blog has mentioned this event. Therefore, we must say that DataJoy really did not do enough promotion.
I also used DataJoy to perform data analysis experiments and even run examples of MNIST character codes identified through Kerras deep learning. But when doing my own convolutional neural network experiment, DataJoy's computing power is far from enough. The running speed of its own DataJoy server is relatively slow, and it sets a limit on the running time of a single project. Even if I pay for it to extend the project running time, it is far from enough to perform the computing power required for the experiment. This may also be related to the market positioning of the DataJoy website. DataJoy is different from Sense's positioning, not specifically for data analysis, but for programming introductory education. But in fact, it is very likely that because of the limited computing power of DataJoy, it can only be limited to applications with limited education and computing power. But DataJoy's interface and interaction are indeed very intimate, after all, there is ShareLaTeX maintenance experience.
From the point of view of the site's own capabilities, DataJoy is not outstanding, but considering its operation is the ShareLaTeX team, its growth is very much what I expected. The reasons for this are a bit complicated and involve a complex issue.
In the academic field, the reproducibility of scientific research results has always been a big headache. In the computer field, it is often at the same time that the paper is published, and then a code for the relevant method is issued. But after all, it is really difficult to compare two different kinds of work, writing academic documents and compiling code. At the same time, in the process of scientific research, the compilation of experimental code and the writing of academic documents were completely separated, which also caused repeated interruptions and handovers of the scientific research process.
In R language, a revolutionary tool knitr has emerged in recent years.
Knitr is an open-source R code package developed by Dr. Xie Yihui during the reading of the Doctor of Statistics. After graduation, Dr. Xie entered the RStudio company full-time development of R language tools. With knitr, experiment records, reports, and presentations with R code can be written directly. The R code in the document can be directly executed and the result can be output to a document, such as the data of the experiment result, the line graph according to the experiment and the result table of the comparison experiment, and the like. This process is similar to Jupyter in programming languages. Code and documentation are written alternately, and source code, data analysis results, and documents alternately appear.
The difference is that knitr can compile Rmd (R language-enhanced markdown variants) into text documents and eventually generate academic-quality printable PDF documents. This program makes academic writing, data analysis source code and experimental results, and even graphic presentations all merge into the same process. First of all, for the repeatability of scientific research results, the reader can directly run the code in the document to reproduce the experimental results. Second, the scientific research process is also a great simplification, and the scientific research workflow and academic writing process are integrated and greatly simplified.
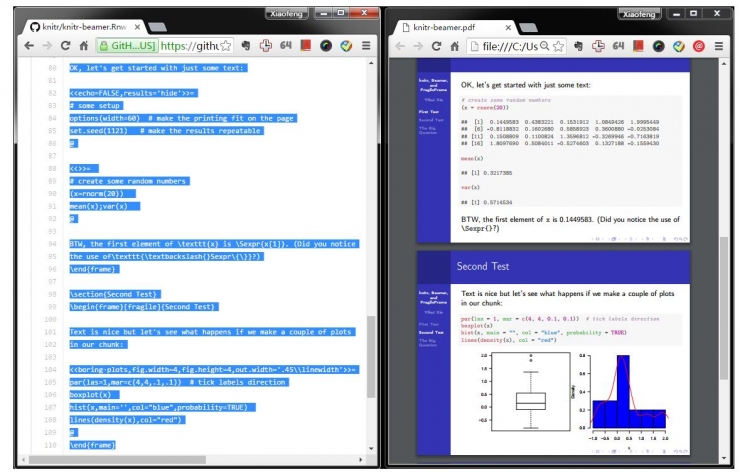
Knitr Example of embedding experimental code output in Beamer. The blue on the left is the original Rmd file, and the right is the generated PDF presentation report document. The block of R code that starts with `<<>>=` and ends with `@` will run automatically. The output control parameters for the contents of the loaded document can be written in `<<>>`. For example: `<
DataJoy, a cloud computing platform that supports Python and R code execution, gives users a great deal of imagination because of its ShareLaTeX (professional online LaTeX document authoring platform) background. After all, Python is much more pervasive than R. There is a rich code base for various data analysis and deep learning, and the basic operation of DataJoy is very easy to further expand and support more programming languages ​​(see Beaker Notebook supports almost all languages. ). If the integration between ShareLaTeX and DataJoy can be effectively integrated, academic publishing, technical document writing, data science teaching, programming teaching, big data, and artificial intelligence research and teaching will be fully opened.
Unfortunately, DataJoy did not go this far. Do not know whether the team's positioning problem for DataJoy, or the recent capital winter caused the concept can not continue. Originally, the imaginative platform has become isolated.
| Collaboration-oriented cloud computing platformCloud data analysis platform in addition to open source tools such as Jupyter and beakernotebook.com. The websites of commercial operations are mainly successful for a few sites such as large enterprises business intelligence analysis, financial quantitative analysis and data analysis contest. The main reason is that while data analysis is hot in related industries, it is actually a relatively niche area. Especially among these few industry players, concerns about the leakage of data and algorithms have added to the doubts about using open platforms.
Only in the areas of education, academics, and recruitment, due to its inherent openness, the relevant platforms have a certain market. But this has a population base problem. Facebook's target users can be all the people in the world, and now reach 1.7 billion monthly live; the target users of GitHub can be all programmers in the world, and currently have about one million live monthly; the target users of a data analysis platform are just programs. How much will the staff do in the direction of data analysis? It is not difficult to explain why such websites are relatively difficult to succeed.
But in China, this is another story. On July 15, 2016, Thomson Reuters sold its intellectual property business and scientific information business to Onex Corp and Barings Asia Investment for US$3.55 billion. The sale of SCI's science citation index service by the parent company sounded a wake-up call for China. The country’s dependence on intelligence and the nation’s evaluation standards for academic research have not only been left alone, but have also been commercialized by Eastern and Western sales. The evaluation of national scientific research results and the orientation of topic selection are held in the hands of commercial companies, and the development of domestic academic publishing cannot be delayed. However, the long-term use of SCI as an evaluation standard is a last resort. Its objective and peer-review mechanism is the necessary dependence on Chinese academic research for a long time. Therefore, an objective, neutral and open domestic academic publishing solution actually has a strong demand.
In academic research fields such as computer vision, machine learning, and artificial intelligence, academic articles have become popular in recent years:
The PDF text is published on arXiv; the code is published on GitHub so that there is a dedicated GitXiv index of such papers and code.
From this promotion, if there are enough resources, through acquisition or collaboration to open up a series of websites, to establish a common platform to achieve a complete scientific research, technology, industrial ecological chain, including: An online learning like OverLeaf or ShareLaTex Document collaboration authoring platform, a collaborative cloud computing platform like Sense.io or DataJoy, an extremeview.mo algorithmic monetization platform, a Kaggle-like algorithmic competition platform, and a data hosting platform.
Domestic artificial intelligence, robotics, machine learning, computer science academic research and entrepreneurship all require such a universal cloud computing platform to open up academic research, academic publishing, academic achievement evaluation, online data analysis competition and collaboration, and selection of scientific and technological talents. , academic achievements and other fields. Here, it is strongly recommended that people of insight establish an online cloud computing collaboration platform.
| ConclusionIn the era of cloud computing, how to assemble a set of academic research or data analysis tool chain on the "cloud" is one of my major concerns in recent years. The various existing cloud services are blooming, but there has been no strong driving force to integrate these cloud services. This cold winter of capital now provides an opportunity for various entrepreneurial companies to warm up, open up ecological chains, collaborate on innovation, and optimize and upgrade. It is hoped that the data entrepreneurs can turn the crisis into a machine and successfully survive the cold winter and create a new digital future.
Maskking(Shenzhen) Technology CO., LTD , https://www.szdisposableecigs.com